
Gender Representation on the Internet
In which I discover that male names appear much more often than female names on the Internet.
Tagged:
Data Science
There is a lot that has happened since last August. I successfully defended my Ph.D., for one. I could give a report on our post-defense trip to Spain. I could talk about some interesting work I'm now doing. Instead, I'm going to devote this blog entry to gender inequity.
This all started in November of last year in response to one of Dave's blog posts. Long-story-short, he was blogging about a girl he had met; in an effort to conceal her identity (lest she discover the blog entry about herself), he replaced her name with its MD5 hash. Curious, I decided to brute force the hash to retrieve her actual name. This was very simple in Perl:
#!/usr/bin/perl -w
use Digest::MD5 qw(md5_hex);
my $s = $ARGV[0] or die("Usage: crackname MD5SUM\n\n");
system("wget http://www.census.gov/genealogy/names/dist.female.first") unless(-e 'dist.female.first');
open(NAMES, 'dist.female.first') or die("Error opening dist.female.first for reading!\n");
while() {
if($_ =~ m/^\s*(\w+)/) {
my $name = lc($1);
if(md5_hex(ucfirst($name)) eq $s || md5_hex($name) eq $s ||
md5_hex(ucfirst($name) . "\n") eq $s || md5_hex($name . "\n") eq $s) {
print ucfirst($name) . "\n";
exit(0);
}
}
}
close(NAMES);
exit(1);
Note that I am using a file called dist.female.first, which is freely available from the US Census Bureau. This file contains the most common female first names in the United States, sorted by popularity, according to the most recent census.
This script was able to crack Dave's MD5 hash in about 10 milliseconds.
This got me thinking: For what else could this census data be used?
My first idea was also inspired by Dave. You see, he was writing a novel at the time. Wouldn't it be great if I could create a tool to automatically generate plausible character names for stories?
#!/usr/bin/perl -w
use Cwd 'abs_path';
use File::Basename;
my($scriptfile, $scriptdir) = fileparse(abs_path($0));
my $prob;
$prob = $ARGV[0] or $prob = rand();
system("cd $scriptdir ; wget http://www.census.gov/genealogy/names/dist.all.last") unless(-e $scriptdir . 'dist.all.last');
system("cd $scriptdir ; wget http://www.census.gov/genealogy/names/dist.male.first") unless(-e $scriptdir . 'dist.male.first');
system("cd $scriptdir ; wget http://www.census.gov/genealogy/names/dist.female.first") unless(-e $scriptdir . 'dist.female.first');
sub get_rand {
my($filename, $percent) = @_;
open(NAMES, $filename) or die("Error opening $filename for reading!\n");
$percent *= 100.0;
my $nameval = -1;
my @names;
my $lastname;
while() {
if($_ =~ m/^\s*(\w+)\s+([^\s]+)\s+([^\s]+)/) {
$lastname = ucfirst(lc($1));
if($3 >= $percent) {
last if($nameval >= $percent && $3 > $nameval);
$nameval = $3;
push(@names, $lastname);
}
}
}
close(NAMES);
return $lastname if($#names < 0);
return $names[int(rand($#names + 1))];
}
sub random_name {
my($male, $p) = @_;
my $firstnameprob;
my $lastnameprob;
do {
$firstnameprob = rand($p);
$lastnameprob = $p - $firstnameprob;
} while($lastnameprob > 1.0);
return &get_rand($male ? 'dist.male.first' : 'dist.female.first', $firstnameprob) . " " . &get_rand('dist.all.last', $lastnameprob);
}
sub flushall {
my $old_fh = select(STDERR);
$| = 1;
select(STDOUT);
$| = 1;
select($old_fh);
}
print STDERR "Male: ";
&flushall();
print &random_name(1, $prob) . "\t";
&flushall();
print STDERR "\nFemale: ";
&flushall();
print &random_name(0, $prob) . "\n";
This script does just that. Given a real number between 0 and 1 representing the scarcity of the name, this script randomly generates a name according to the distribution of names in the United States according to the census. Values closer to zero produce more common names, and values closer to one produce more rare names. The parameter can be thought of as the scarcity percentile of the name; a value of $x$ means that the name is less common than $x$% of the other names. Note, though, that I'm not actually calculating the joint probability distribution between first and last names (for efficiency reasons), so the value you input doesn't necessarily correlate to the probability that a given first/last name combination occurs in the US population.
$ ./randomname 0.0000001 Male: James Smith Female: Mary Smith $ ./randomname 0.5 Male: Robert Shepard Female: Shannon Jones $ ./randomname 0.99999 Male: Kendall Narvaiz Female: Roxanne Lambetr
The "Male" and "Female" portions are actually printed to STDERR. This allows you to use this in scripting without having to parse the output:
$ ./randomname 0.75 2>/dev/null Gerald Castillo Christine Aaron
But I didn't stop there. Here's the punchline of this Shandy-esque recount:
Inspired by Randall Munroe style Google result frequency charts, I became interested in seeing how the frequency of names in the US correlates to the frequency of names on the Internet. I therefore quickly patched my script to retrieve Google search query result counts using the Google Search API. I generated 60 random names (half male, half female) for increasing scarcity values (in increments of 0.01). The results are pretty surprising:
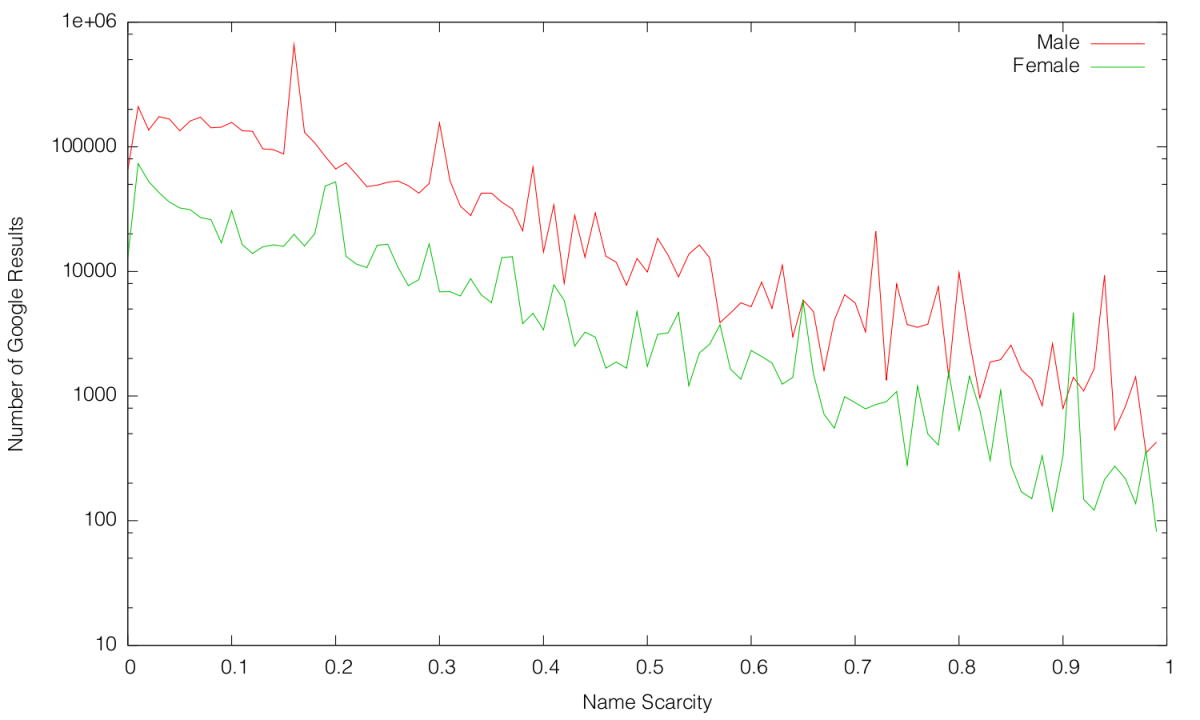
Note that the $y$-axis is on a logarithmic scale.
As expected, the number of Google search results is exponentially correlated to the scarcity of the name. What is unexpected is the disparity between representation of male names on the Internet versus female names on the Internet. On average, a male name of a certain scarcity will have over 6.6 times more Google results than a female name of equal scarcity!