 PoC‖GTFO
PoC‖GTFO LinkedIn
LinkedIn GitHub
GitHub XTerm
XTerm
 English
English
 עברית
עברית
 Medžuslovjansky
Medžuslovjansky
 Русский
Русский
Recent Content:
PoC‖GTFO Issue 0x12
COLLECTING BOTTLES OF BROKEN THINGS, PASTOR MANUL LAPHROAIG WITH THEORY AND PRAXIS COULD BE THE MAN WHO SNEAKS A LOOK BEHIND THE CURTAIN!

PoC‖GTFO Issue 0x11
IN A FIT OF STUBBORN OPTIMISM, PASTOR MANUL LAPHROAIG AND HIS CLEVER CREW SET SAIL TOWARD WELCOMING SHORES OF THE GREAT UNKNOWN!

PoC‖GTFO Issue 0x10
IN THE THEATER OF LITERATE DISASSEMBLY, PASTOR MANUL LAPHROAIG AND HIS MERRY BAND OF REVERSE ENGINEERS LIFT THE WELDED HOOD FROM THE ENGINE THAT RUNS THE WORLD!

PoC‖GTFO Issue 0x09
PoC ‖ GTFO PASTOR MANUL LAPHROAIG'S TABERNACLE CHOIR SINGS REVERENT ELEGIES OF THE SECOND CRYPTO WAR

PoC‖GTFO Issue 0x08
AS EXPLOITS SIT LONELY, FORGOTTEN ON THE SHELF YOUR FRIENDLY NEIGHBORS AT PoC ‖ GTFO PROUDLY PRESENT PASTOR MANUL LAPHROAIG'S EXPORT--CONTROLLED CHURCH NEWSLETTER

Service Discovery on Dynamic Peer-to-Peer Networks Using Mobile Agents
or, How Bumper Cars Relate to Computer Science
The absurd realization that it has almost exactly been a decade since I defended my master’s thesis took me by surprise. It seems like yesterday. That work has had some decent exposure over the years, but, like most creative works produced toward the beginning of one’s career, I do not look back on it as a paragon.
Moshe Kam, upon reading a preliminary draft, summarized it very well:
[It] reads like Tristram Shandy, but devoid of humor.He was referring to my organization of one particular chapter: First I described the overall technique, then I proceeded to iteratively break the problem into successively smaller chunks. A bit like taking apart a matryoshka doll. Or maybe a more apt analogy would be: peeling away the layers of a rotten onion only to find a miniscule, barely salvageable core, calling into question the cost/benefit of the whole excavation. Moshe was right. With that said—and unlike the eponymous biographee of the aforementioned book—I think I can at least claim that my ideas are fully “born” in the first volume.
Despite somehow managing to get that chapter of my thesis published in a book, I feel like it always suffered from my cumbersome presentation. Therefore, perhaps inspired by Stetson hats and hip flasks, I have since devised an analogy that I hope at least makes the problem (if not my solution) more accessible. That’s what I am going to describe in the remainder of this post.
Consider, for a moment, that you are piloting a car in a huge bumper car arena.

CC BY 2.0, adapted from here
You have some control over your own movement, but there are so many others driving around in the arena that there are constant, unavoidable collisions that throw you off course. From afar, everyone’s movement seems random.
The challenge is that you need to know the time, but you do not have a watch. In fact, there are very few others that have a watch. How do you find the time?
The naïve solution is to simply yell out, “Who has the time‽” The problems with this solution are:
- If everyone needs to know the time at once, there will be very many yelling people.
- What if no one with a watch can hear you? Bumper car arenas tend to be loud.
A slightly more intelligent approach might be to:
- Take a piece of paper and write a request on it for the current time.
- Pass the piece of paper to the next person who bumps into you.
- If one who is watch-less receives such a piece of paper, he or she passes it on to the next person that bumps into him or her.
- When the note eventually reaches someone with a watch, he or she will write the current time on the piece of paper and send it back to you.
The obvious shortcomings to this approach, however, are that:
- When the note eventually gets back to you, the time will be incorrect!
- What if, in fact, no one has a watch? How long do you have to wait without receiving a response before you can be sure that no one has a watch?
- What if not everyone speaks and/or reads English?
My realization is that: If one roughly knows the topology of the network (i.e., the locations of all of the cars), and if the messages are truly passed randomly through the network, one can use ergodic theory and random graph theory to accurately predict the frequency of message arrivals. Assuming knowledge of the network topology is reasonable, since many ad hoc networking algorithms already provide it. Even if it is not available, an approximation of the topological properties is often sufficient. So, what this provides is a model for predicting how long it will take for one’s message to eventually reach someone with a watch and, subsequently, how long it will take for the response to be returned. What I discovered was that the variance is often small enough such that this estimate can be used to correctly adjust for the delay in returning the time. Furthermore, this model provides a probability distribution for how likely it is that one would have received at least one response as a function of waiting time. Therefore, if n seconds have passed and the model says that with probability 0.99 one should have received a response to the time query, yet no response has been received, one can conclude with 99% certainty that there is no one in the network with a watch!
The last challenge question, “What if not everyone speaks and/or reads English?” will have to wait for another post…
It’s been a week since the tragic Amtrak derailment in my home town of Philadelphia. Being an avid train passenger—commuting to and from DC several times per week—and having taken the ill fated Northeast Regional Train No. 188 on multiple occasions, this has struck close to home. I am posting this blog entry from the café car of Train No. 111, the first Southbound train to commence full Amtrak service since the disaster.
I realize that it is very early, and the National Transportation Safety Board investigation is still ongoing. Speculation—especially by someone like me who is not a transportation expert—would be unproductive at best, and offensive to the victims at worst. Perhaps it’s my job as a security professional—in which I am paid to find vulnerabilities in systems … or perhaps it’s the recent spate of news that both cars’ and even commercial airplanes’ heavily computerized control systems can be commandeered, wirelessly, by a remote attacker … or perhaps it is the fact that the crash occurred immediately after national rail safety week and on the eve of a legislative debate on cutting Amtrak funding … or perhaps I’ve just been reading too much Pynchon… but ever since I heard that the train was speeding and that there is no direct evidence incriminating the train operators of negligence (other than the speed), the first thing that popped into my mind was: Software. I haven’t heard anyone (other than well-known security expert Simson Garfinkel) discuss it, so that’s what I’m going to do in the remainder of this post.
One topic that the media has latched onto is Positive Train Control (PTC): a technology that, if only it had been implemented, is purported to have been able to avert the crash. What the media doesn’t say is that the ACS-64 locomotive that was pulling the fateful train was already equipped with PTC. You see, the Advanced Civil Speed Enforcement System (ACSES)—Amtrak’s version of PTC for the Northeast Corridor—requires components both on-board the locomotive and wayside (on the tracks). In other words, PTC will only be fully functional if both the locomotive and tracks are upgraded. Portions of track South of Philadelphia and North of New York already have support. In the case of the Philadelphia crash, the locomotive was a new model that had support, but the tracks on which it derailed did not.
I contend that a software bug in the ACSES system should not be ruled out as a potential cause of or contributing factor to the derailment. Let me be clear: I am not claiming that software was a likely cause of the crash. I am neither a transportation expert nor do I have any detailed knowledge of the ACSES implementation. The purpose of this article is to provide enough evidence that software errors are a plausible enough explanation that the possibility should at least become a part of the public discussion.
There is a reasonable precedent of software bugs causing physical catastrophes. For example, a software bug in Toyota’s electronic throttle control system recently caused the massively publicized “unintended acceleration” problem in many of their vehicles, killing at least 89 people as a result. In 2007, a group of six F-22 Raptor fighter jets experienced multiple computer crashes coincident with crossing the international dateline caused by a software bug that did not anticipate that corner case. The planes lost all navigation and communication, and were only able to make it back to land by following their tankers. Vehicles and transportation systems in general are so complex, automated, and computerized these days that a single software bug can wreak havoc.
But how could a system that is intended to provide a safeguard against crashing actually cause a crash?
A relatively recent report to congress by the Federal Railroad Commission on the implementation of PTC states that ACSES has control over the
…event recorder, train line data sensors, horn circuit, brake systems, cab signal system (if equipped), and the Communication Segment.So, presumably, the system has no control over acceleration, just deceleration.
I am perhaps about to delve too far into the sea of speculation, but as James Burke so eloquently demonstrated, a failure in one system can cascade to cause failures in seemingly independent and unconnected others.
A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable.There is a display in the cab of the locomotive with a speedometer, looking something like this:


CC BY-SA 3.0, from here
When the track is PTC-enabled, there is a second speed readout on the bottom, showing the maximum speed allowed on the track. When the track is not PTC-enabled, the readout looks as pictured here. If the conductor or engineer is relying on that display to gauge the train’s current speed, he or she is thereby relying on the output of ACSES’s algorithms, programming, hardware, and sensors. A failure in any of those pieces could result in an incorrect speed readout, e.g., causing one to believe that the speed of the train were actually slower than in reality. This is similar to how Air France Flight 447 was doomed by an engineering design flaw in its airspeed sensors, which caused a failure in the autopilot software, which reported inaccurate instrumentation to the pilots, who relied upon the incorrect information, making manual piloting errors that caused the plane to crash.
I do not wish the tragedy of Amtrak Train No. 188 on anyone; it could have very easily been me sitting in that café car a week ago. While history has proven that human error is the most frequent cause of these types of accidents, we increasingly need to also look at the software for possible fault.
I’ve been regularly commuting between Philly and DC on Amtrak for over six months now. Being in the Northeast corridor—the only profitable region in Amtrak’s network—and specifically being in the NYC↔Philly↔Washington trifecta that accounts for about a third of Amtrak’s overall nationwide ridership, the service is generally excellent. Not Shinkansen excellent, but good enough to take me where I need to go in relative comfort, in a third less time than would be necessary to drive. And in English, too, so I can die with a smile on my face, without feelin’ like the good Lord gypped me.
For a pseudo-public entity, Amtrak does a surprisingly good job keeping up with the technological times. It’s had free WiFi on its trains for a number of years, the conductors scan tickets using ruggedized iPhones, and its iOS app lets me store and organize my myriad tickets in Passbook. One can even present tickets via an Apple Watch.
The one gripe I have about the system is that, despite Amtrak’s excellent online tools for tracking the exact location of trains, there is no good way to get useful train status alerts. I often work at a location ~45 minutes outside of DC, so I want to know whether my train is delayed before I depart for the station.
The Southbound trains I take from Philadelphia originate in either New York or Boston. Therefore, I want to get an alert texted to my phone when the train has departed New York. If it departed New York on time, then I can proceed as normal. If it was delayed, then I can hit the snooze button. If it didn’t even leave yet, then I know that it will be at least an hour before it arrives in Philly.
The first thing I had to do was figure out a way to send text messages for free. Every major cellular provider has some sort of gateway service where an E-mail sent to the proper address will be forwarded to the associated phone number. Therefore, I created a simple Python library (in pure Python; no dependencies) for sending free (to the sender) text messages to phones from every major international carrier:
Next, I had to reverse engineerdevise a way to get
accurate train status updates. This was relatively straightforward,
but I hesitate to go into details because it might implicate me in
several terms-of-use violations.
I pieced this all together into a new service that I have been using and allowing several fellow commuters to beta-test for the past couple months. I’m excited to release it to the public now:
This website has no affiliation with any railways or train operators. If you are a railway or train operator, please keep in mind that this is a toy website created by a single guy with altruistic motives. Please don’t sue me. Instead, let’s talk about how I can give you what I’ve created here so that you might host it and provide it as a service for your customers.
No profit is made off of the services on this website. In fact, I lose money by running it. Therefore, there are certain concessions that have been made due to lack of fuding. Namely, there is the possibility that a malicious party could illegally intercept the messages sent between a user’s web browser and this server, potentially altering his or her account and alerts. I have implemented as many security features as possible to protect against this, but in order to be almost foolproof I would need to host the site on SSL, which requires money. If you desire additional security and features, please consider donating.
Enjoy, and please drop me a line if you find the service useful!
Recently, a friend of mine shared a link to Max Richter’s solo debut album Memoryhouse on social media:
While I appreciate Richter’s work and think it’s good, it’s very hard for me to enjoy it. The problem is that I find much of it—and particularly Memoryhouse—too reminiscent of Philip Glass’. The latter’s minimalism and distinctive brand of ostinato, harmonic chord progressions, variations in half-time, &c., is clearly being referenced in Memoryhouse, albeit with perhaps “post-minimalist” orchestration. For example, when I first listened to November, the first track of Memoryhouse (q.v. above), it immediately reminded me of Glass’s String Quartet No. 3, which predates Memoryhouse by about 20 years:
It’s a bit like when a TV show wants to parody Jeopardy but doesn’t have the budget to license rights to the Jeopardy Think! music, so it creates a slightly different version which ends up sounding wrong, despite the fact that if the original Jeopardy theme had never existed this new version would be just as popular. What is called a musical pastiche.
That just sounds wrong to me, to the extent that my subconscious is offended by it. It’s like going to a Michelin 3-starred restaurant and being served artisanal, house-made ketchup, from locally sourced organic tomatoes and garlic harvested from the chef’s own private garden during the last full moon in spring: No matter how good that ketchup tastes, it’s not going to taste as right as Heinz, because that’s what you grew up eating. And heaven forbid you’re served Hunt’s. Did we lose a war?
In my mind, a pastiche is distinct from something like an homage or inspiration since its similarity to the source material is much more noticeable. For example, Glass’s predilection for pairing low-pitch ostinato with higher-pitch simple melodies is technically very similar to Mozart’s modus operandi, yet we rarely ever hear Glass being directly compared to Mozart.
A number of years ago I had a subscription to the Philadelphia Orchestra and attended a concert debuting a new symphony by a relatively unknown composer (whose name escapes me). The theme was “The United States.” I’m guessing the concert was held around the time of Independence Day, but I neither remember nor care to look it up. The whole thing was very frustrating for me to sit through, because it was clear to me that every single movement was simply a pastiche of the work of a much more famous American composer. I would have much rather heard a performance of “the real thing.”
Music from completely different genres can also either purposefully or accidentally trick our brains into finding similarity. From almost exactly five years ago today:

 Reply
Reply Retweet
Retweet Favorite
Favorite
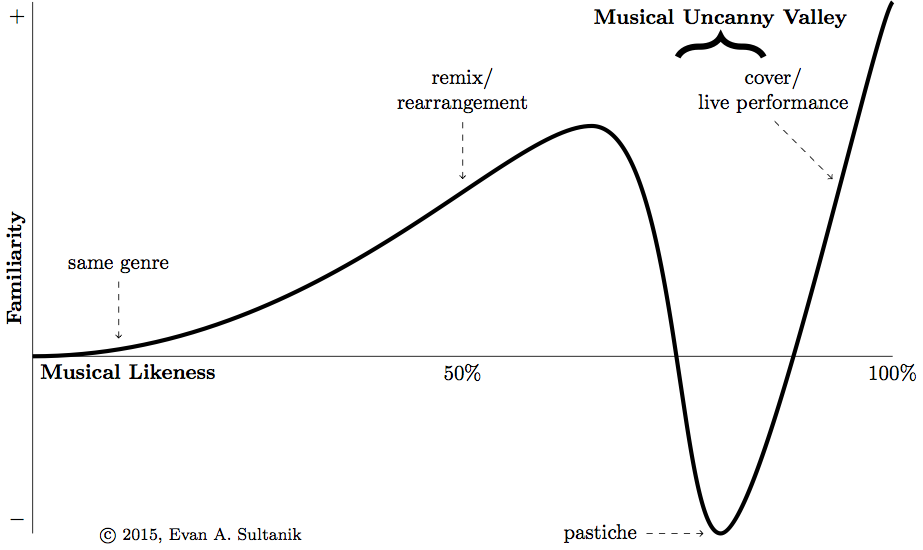
The field of æsthetics has produced a hypothesis of what is know as the uncanny valley: When an object moves and/or looks very similar to (but not exactly like) a human being, it causes revulsion to the observer. Here is a video with some examples, if you want to be creeped out a bit. As objects become increasingly similar to the likeness of a human, human observers become increasingly empathetic toward the object. However, once the object passes a certain threshold of human likeness, the human starts to be repulsed, until another likeness threshold at which point the object is almost indistinguishable from a real human.
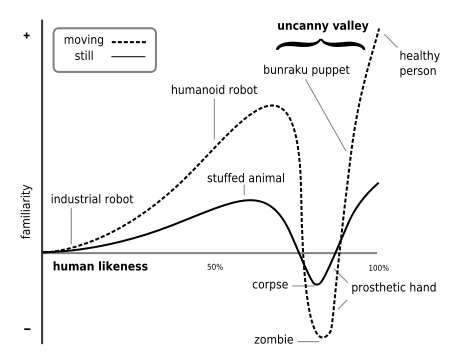
CC BY-SA 3.0, from here
I posit that there is a similar phenomenon in music, and that is what I am experiencing when I listen to Memoryhouse. One of the theories explaining the uncanny valley is that conflicting perceptual cues cause a sort of cognitive dissonance. It is well-known that the brain behaves almost identically when imagining a familiar piece of music as it does when listening to it. This suggests that the brain is internally “playing” the music in synchrony with what it is hearing, anticipating each note. In a sense, one’s brain is subconsciously humming along to the tune. My theory is that when a song (or, particularly, a pastiche) is similar enough to another song that is much more familiar, this evokes the same synchronous imagining. However, once the pastiche deviates from anticipated pattern, this ruins the synchrony and causes cognitive dissonance.
Excuse the pun, but on that note I’ll leave you with something that will hopefully not be in your musical uncanny valley: This wonderful, recent recomposition of Glass’s String Quartet No. 3 for guitar: